- The Web Scraping Insider
- Posts
- The Web Scraping Insider #6
The Web Scraping Insider #6
Your high-signal, zero-fluff roundup of what’s happening in the world of professional web scraping.
Ian Kerins
March 18, 2026 • Estimated Reading Time: 3 minutes

👋 Hello there!
Welcome to the sixth edition of The Web Scraping Insider, by the ScrapeOps.io team.
With this newsletter, you get a zero-fluff roundup of what actually matters in professional web scraping, grounded in production data, not marketing decks.
Let's get to it!
🤖 We Built "Lovable for Scrapers" and We're Opening It to Newsletter Readers
What happens when the cost of building a scraper drops to ~$2?
The whole game changes.
Scrapers stop being "projects" and start becoming disposable infrastructure.
That's the shift we've been working towards over the last 8 months and why we built our AI Scraper Builder.
⚙️ What it does
Simply give it a few example URLs (product pages, listings, articles, etc.), and it generates working scraping code in minutes.
Under the hood it:
fetches and parses sample pages
infers a data schema from the pages
generates framework-specific code (Python/Node with Playwright, Puppeteer, Scrapy workflows)
runs validation passes and auto-fixes failures
This is not "prompt and pray." It's generation + validation + repair in one loop.
💸 Why this matters (the economics)
The core shift is simple:
When scraper generation costs approach zero (we're seeing $1-$4 per scraper), the bottleneck shifts from "can we build this?" to "is this source worth tracking?"
That unlocks three immediate advantages for developers & businesses:
More source coverage without linear developer time growth
Faster product experiments because prototype scrapers stop being expensive setup work
Less maintenance drag so dev time goes to data quality and pipeline reliability, not endless parser patching
This is exactly the pattern we've been discussing in recent issues: cost is moving up the stack. If you reduce generation/maintenance friction, your unit economics improve even when anti-bot complexity rises.
🧪 Beta status
We ran a private beta with ~200 developers stress-testing real workflows, got blunt feedback, and now we're opening public beta next week.
20 free generations
no card required
we only ask for honest feedback from production use cases
🧠 Copyright Guardrails for Scraping: Facts vs Expression Still Matters
A strong practical guide from The Web Scraping Club breaks down where copyright risk usually appears in scraping pipelines: copied editorial text, images/media reuse, and dataset-scale replication of creative expression.
The most useful framing is operational, not theoretical:
scrape facts, not expression
transform, don't replicate
avoid storing full raw pages by default
treat images/media as a higher-risk class
separate technical capability from legal permission
Our take: most legal risk is process failure, not parser failure. If your default pipeline stores everything "just in case," you're creating avoidable exposure.
Imagine paying $300/month for a "Stealth" Brower API only for it to leak cdpAutomation=true to every anti-bot system it sends requests to.
Unfortunately, this isn't hypothetical. It is really happening.
We benchmarked popular Stealth Browser APIs, and the results were very clear:
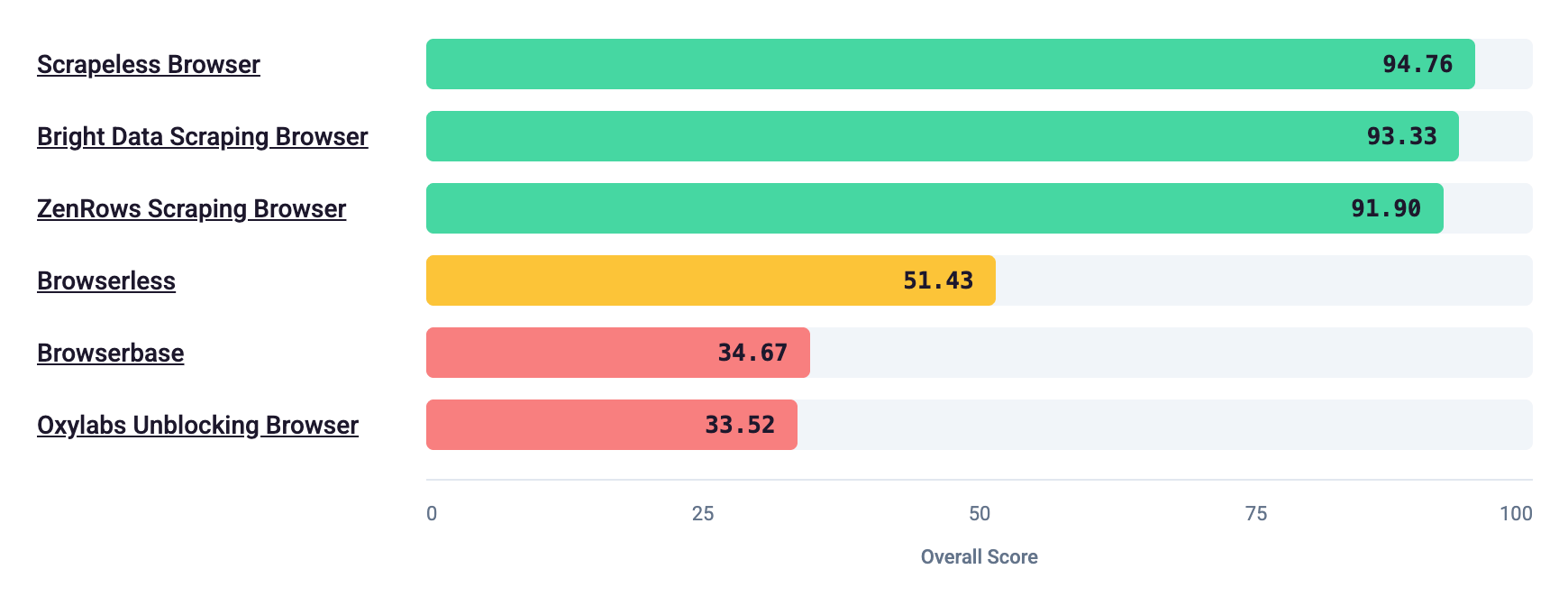
🥇 Top performers
Scrapeless Browser
Bright Data Scraping Browser
ZenRows Scraping Browser
All three scored near the top. The remaining issues were mostly localization consistency (same timezone/language reused across regions), not catastrophic automation leakage.
That's an important point: good stealth browser implementations can provide real value when done properly.
⚠️ Weak performers
Browserless (Stealth)
Browserbase (Stealth)
Oxylabs Unblocking Browser
Common failure patterns:
explicit automation fingerprints
misaligned UA and browser internals
server-grade hardware signals
static/low-entropy fingerprints
💡 Our take
The old rule continues to hold:
Price has a weak correlation with real stealth quality.
You should evaluate providers like any serious dependency:
benchmark your exact targets, inspect fingerprint leaks, and keep fallback routing ready.
If your stack isn't measuring stealth integrity continuously, you're effectively flying blind.
☁️ Cloudflare's /crawl Endpoint: Useful Infrastructure, Not the End of Scraping
Last week, social media was awash with people posting hot takes about how Cloudflare's new crawler endpoint is the end of web scraping.
However, most of those takes skipped one important step:
This Cloudflare /crawl endpoint is powerful. Think of /crawl as a managed crawler on Cloudflare browser infrastructure for sites that explicitly allow bot access.
But if you read the docs, they explicitly say:
It identifies itself as a bot
It respects robots.txt
It does not bypass CAPTCHAs, WAF, or Bot Management
Site owners can still block it
So no, the /crawl endpoint will not "kill scraping."
However, it is another step toward a permissioned, pay-to-crawl lane between AI crawlers and publishers.
If publishers choose to adopt this mechanism, the price they will charge for access remains to be seen.
👀 Insider take
Until the price websites are willing to pay to open access to their data, and the cost of scraping the data via proxies converges sufficiently, the web scraping landscape will remain unchanged.
💸 HTTP Conditional Requests: The Most Underused Cost Lever in Scraping
The Web Scraping Club's LAB #99 highlights a simple but powerful truth: many teams are still paying for full-page fetches when nothing has changed.
Using ETag/Last-Modified with If-None-Match / If-Modified-Since lets servers return 304 Not Modified with zero response body. For bandwidth-priced proxy workloads, this can materially cut recurring costs.
Given the recent Scraping Shock economics (proxy prices down, cost-per-success up), this is the kind of boring optimization that actually moves margin.
Our take: before adding another anti-bot vendor, audit how many recurring requests could be downgraded to conditional checks.
Best fit: recurring monitoring (price tracking, stock checks, catalog freshness).
Operational benefit: less wasted bandwidth on unchanged pages.
Implementation cost: low, if your crawler stores per-URL validator headers.
🚀 Until next time
That's a wrap for #6. If this helped, share it with someone running scraping workloads at scale.
Ian from ScrapeOps